
Representation Learning in Knowledge Graphs
Most current machine learning methods require an input in the form of features, which means they cannot directly use a (knowledge) graph as input. For this reason, we aim to learn feature representations of entities and relations in the knowledge graph. This is called representation learning and the same idea is not just applied to graphs – but also images, (unstructured) texts, audio or video. Those representations are also called embeddings. Of course, the learned representations should not be arbitrary: ideally, they should allow downstream machine learning tasks to perform well. The image below shows how the nodes for Barrack and Michelle Obama are transformed to a 2-dimensional feature space (in practice the number of dimensions is much higher).
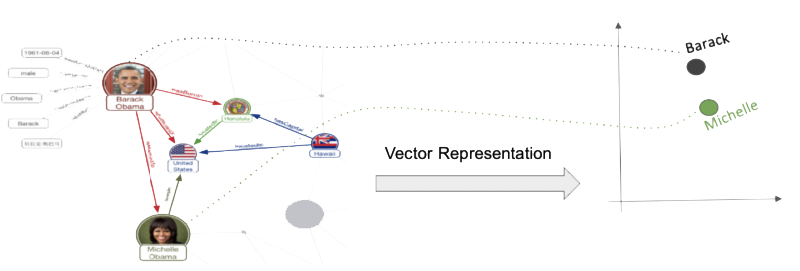
Knowledge graphs contain triples of the form (subject, predicate, object). The basic idea of most knowledge graph representation learning (KGRL) models is to learn representations, such that the feature representation of the subject transformed by a predicate or also called relation specific transformation results in the object representation. A drawback of most models is, however, that they often only support a single or few types of transformation. This directly affects which graph structure and semantics they can preserve. For example, in the TransE model all symmetric relations will (when only considering the transformation function) actually have embeddings whose latent feature vectors are close to 0 and all entities involved in symmetric relations will have very similar embeddings as a result. Trying to preserve as much structural and semantic aspects in the vector space in KGRL models is one of the main aims of our research.
In a paper published at AAA 2021, we propose to use projective geometry, which allows to use five simultaneous transformations – inversion, reflection, translation, rotation and homothety. In our model 5-star, we use complex numbers with real and imaginary parts in projective geometry. A complex number is represented by a point in the complex plane you can see at the bottom of each image part here. The transformation works by first projecting a point in the complex plane to a point in the sphere. This is the so-called Riemann Sphere, which is a representation for the complex numbers extended by infinity. We then move the sphere to a new position in the second step and in the third step project the result back to the complex plane.
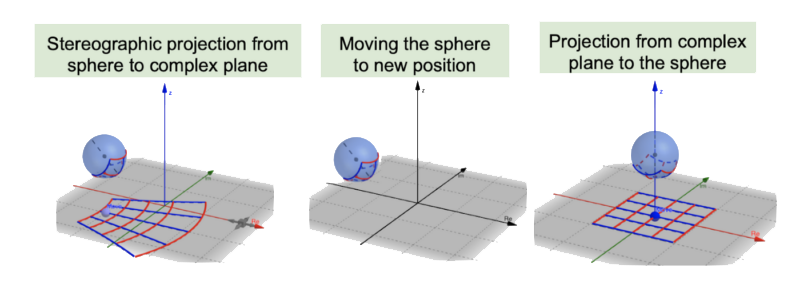
Apart from the performance in practice, a nice thing is that we could also prove some formal properties. We could show that the model is fully expressive. A model is fully expressive if it can accurately separate existing and non-existing triples for an arbitrary KG. We could also show that the model is capable to infer several relational patterns, in particular role composition, inverse roles and symmetric roles. Inference here means that when the premise is true according to the score function of the model, then the conclusion is also true. Last, but not least, we could show that the model subsumes various state-of-the-art models. Subsumes here means that any scoring for an arbitrary KG of a model can be achieved by the more general model.
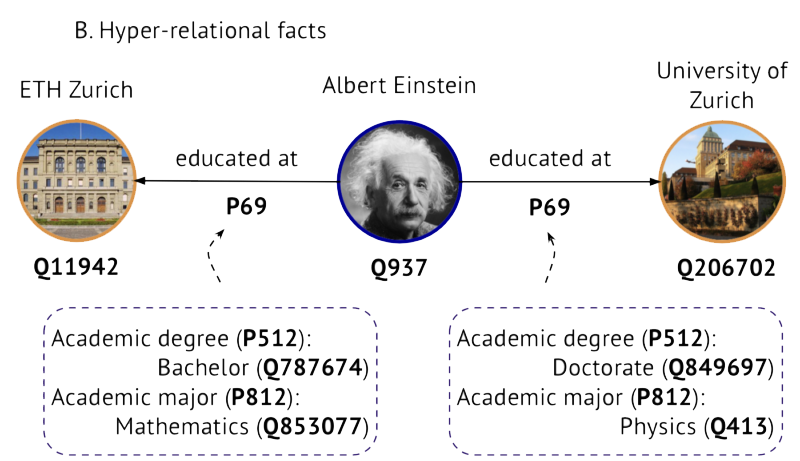
We worked on several aspects of KGRL models. For example, in a paper published at EMNLP 2020, we considered hyper-relational facts, i.e. knowledge graphs with further information on edges as shown below. This is employed by some large-scale knowledge graphs like Wikidata and DBpedia. We used graph neural networks to work with such knowledge graphs.
We also worked on the inclusion of numerical and temporal data and are continuously researching KGRL approaches in order to build a bridge between knowledge- and data-driven approaches in AI. We applied the work in biology and scholarly recommendations.
Apart from devising new approaches, one of the major hurdles in KGRL is that approaches are hard to compare against each other as subtle nuances in the loss functions, metrics and hyperparameters can have a bigger effect on the final results than the actual technical contributions of one particular paper. For this reason, we started the PyKEEN effort, which is meanwhile a community project that has received wide attention, e.g. is used by AstraZeneca. Via PyKEEN, we can directly compare approaches in particular settings in the same environment. We used this to create a large-scale reproducibility study.
It will be very interesting to see to what extend KGRL can be used to include domain-specific and expert information into systems trained on raw data. In particular, as mentioned above, a main question is how much structural and semantic information can be preserved in the embedding space. We have already seen that using different types of geometries can be useful in this regard and we may also explore other formalisms, such as differential equations, work in different settings, e.g. inductive approaches (where parts of the KG are unseen), and last but not least actually apply KGRL in downstream tasks that go beyond link prediction – for example for building intelligent dialogue systems.
Related Publications
Journal Articles
Language Model Guided Knowledge Graph Embeddings Journal Article
In: IEEE Access, 10 , pp. 76008–76020, 2022.
Bringing Light Into the Dark: A Large-Scale Evaluation of Knowledge Graph Embedding Models Under a Unified Framework Journal Article
In: IEEE Trans. Pattern Anal. Mach. Intell., 44 (12), pp. 8825–8845, 2022.
Discover Relations in the Industry 4.0 Standards Via Unsupervised Learning on Knowledge Graph Embeddings Journal Article
In: J. Data Intell., 2 (3), pp. 326–347, 2021.
Link Prediction of Weighted Triples for Knowledge Graph Completion Within the Scholarly Domain Journal Article
In: IEEE Access, 9 , pp. 116002–116014, 2021.
Trans4E: Link prediction on scholarly knowledge graphs Journal Article
In: Neurocomputing, 461 , pp. 530–542, 2021.
PyKEEN 1.0: A Python Library for Training and Evaluating Knowledge Graph Embeddings Journal Article
In: J. Mach. Learn. Res., 22 , pp. 82:1–82:6, 2021.
CLEP: a hybrid data- and knowledge-driven framework for generating patient representations Journal Article
In: Bioinform., 37 (19), pp. 3311–3318, 2021.
3D Learning and Reasoning in Link Prediction Over Knowledge Graphs Journal Article
In: IEEE Access, 8 , pp. 196459–196471, 2020.
BioKEEN: a library for learning and evaluating biological knowledge graph embeddings Journal Article
In: Bioinform., 35 (18), pp. 3538–3540, 2019.
Inproceedings
Time-aware Entity Alignment using Temporal Relational Attention Inproceedings
In: WWW '22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022, pp. 788–797, ACM, 2022.
Improving Inductive Link Prediction Using Hyper-Relational Facts (Extended Abstract) Inproceedings
In: Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pp. 5259–5263, ijcai.org, 2022.
Dihedron Algebraic Embeddings for Spatio-Temporal Knowledge Graph Completion Inproceedings
In: The Semantic Web - 19th International Conference, ESWC 2022, Hersonissos, Crete, Greece, May 29 - June 2, 2022, Proceedings, pp. 253–269, Springer, 2022.
5* Knowledge Graph Embeddings with Projective Transformations Inproceedings
In: Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pp. 9064–9072, AAAI Press, 2021.
Loss-Aware Pattern Inference: A Correction on the Wrongly Claimed Limitations of Embedding Models Inproceedings
In: Advances in Knowledge Discovery and Data Mining - 25th Pacific-Asia Conference, PAKDD 2021, Virtual Event, May 11-14, 2021, Proceedings, Part III, pp. 77–89, Springer, 2021.
Pattern-Aware and Noise-Resilient Embedding Models Inproceedings
In: Advances in Information Retrieval - 43rd European Conference on IR Research, ECIR 2021, Virtual Event, March 28 - April 1, 2021, Proceedings, Part I, pp. 483–496, Springer, 2021.
Temporal Knowledge Graph Completion using a Linear Temporal Regularizer and Multivector Embeddings Inproceedings
In: Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pp. 2569–2578, Association for Computational Linguistics, 2021.
Embedding Knowledge Graphs Attentive to Positional and Centrality Qualities Inproceedings
In: Machine Learning and Knowledge Discovery in Databases. Research Track - European Conference, ECML PKDD 2021, Bilbao, Spain, September 13-17, 2021, Proceedings, Part II, pp. 548–564, Springer, 2021.
Multiple Run Ensemble Learning with Low-Dimensional Knowledge Graph Embeddings Inproceedings
In: International Joint Conference on Neural Networks, IJCNN 2021, Shenzhen, China, July 18-22, 2021, pp. 1–8, IEEE, 2021.
Time-aware Graph Neural Network for Entity Alignment between Temporal Knowledge Graphs Inproceedings
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pp. 8999–9010, Association for Computational Linguistics, 2021.
Knowledge Graph Representation Learning using Ordinary Differential Equations Inproceedings
In: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pp. 9529–9548, Association for Computational Linguistics, 2021.
Improving Inductive Link Prediction Using Hyper-relational Facts Inproceedings
In: The Semantic Web - ISWC 2021 - 20th International Semantic Web Conference, ISWC 2021, Virtual Event, October 24-28, 2021, Proceedings, pp. 74–92, Springer, 2021.
BenchEmbedd: A FAIR Benchmarking tool for Knowledge Graph Embeddings Inproceedings
In: Joint Proceedings of the Semantics co-located events: Poster&Demo track and Workshop on Ontology-Driven Conceptual Modelling of Digital Twins co-located with Semantics 2021, Amsterdam and Online, September 6-9, 2021, CEUR-WS.org, 2021.
Unveiling Relations in the Industry 4.0 Standards Landscape Based on Knowledge Graph Embeddings Inproceedings
In: Database and Expert Systems Applications - 31st International Conference, DEXA 2020, Bratislava, Slovakia, September 14-17, 2020, Proceedings, Part II, pp. 179–194, Springer, 2020.
Affinity Dependent Negative Sampling for Knowledge Graph Embeddings Inproceedings
In: Proceedings of the Workshop on Deep Learning for Knowledge Graphs (DL4KG2020) co-located with the 17th Extended Semantic Web Conference 2020 (ESWC 2020), Heraklion, Greece, June 02, 2020 - moved online, CEUR-WS.org, 2020.
Embedding-Based Recommendations on Scholarly Knowledge Graphs Inproceedings
In: The Semantic Web - 17th International Conference, ESWC 2020, Heraklion, Crete, Greece, May 31-June 4, 2020, Proceedings, pp. 255–270, Springer, 2020.
Fantastic Knowledge Graph Embeddings and How to Find the Right Space for Them Inproceedings
In: The Semantic Web - ISWC 2020 - 19th International Semantic Web Conference, Athens, Greece, November 2-6, 2020, Proceedings, Part I, pp. 438–455, Springer, 2020.
Knowledge Graph Embeddings in Geometric Algebras Inproceedings
In: Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, pp. 530–544, International Committee on Computational Linguistics, 2020.
Let the Margin SlidE for Knowledge Graph Embeddings via a Correntropy Objective Function Inproceedings
In: 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, United Kingdom, July 19-24, 2020, pp. 1–9, IEEE, 2020.
MDE: Multiple Distance Embeddings for Link Prediction in Knowledge Graphs Inproceedings
In: ECAI 2020 - 24th European Conference on Artificial Intelligence, 29 August-8 September 2020, Santiago de Compostela, Spain, August 29 - September 8, 2020 - Including 10th Conference on Prestigious Applications of Artificial Intelligence (PAIS 2020), pp. 1427–1434, IOS Press, 2020.
Message Passing for Hyper-Relational Knowledge Graphs Inproceedings
In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pp. 7346–7359, Association for Computational Linguistics, 2020.
Temporal Knowledge Graph Completion Based on Time Series Gaussian Embedding Inproceedings
In: The Semantic Web - ISWC 2020 - 19th International Semantic Web Conference, Athens, Greece, November 2-6, 2020, Proceedings, Part I, pp. 654–671, Springer, 2020.
TeRo: A Time-aware Knowledge Graph Embedding via Temporal Rotation Inproceedings
In: Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, pp. 1583–1593, International Committee on Computational Linguistics, 2020.
Linking Physicians to Medical Research Results via Knowledge Graph Embeddings and Twitter Inproceedings
In: Machine Learning and Knowledge Discovery in Databases - International Workshops of ECML PKDD 2019, Würzburg, Germany, September 16-20, 2019, Proceedings, Part I, pp. 622–630, Springer, 2019.
Predicting Missing Links Using PyKEEN Inproceedings
In: Proceedings of the ISWC 2019 Satellite Tracks (Posters & Demonstrations, Industry, and Outrageous Ideas) co-located with 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand, October 26-30, 2019, pp. 245–248, CEUR-WS.org, 2019.
The KEEN Universe - An Ecosystem for Knowledge Graph Embeddings with a Focus on Reproducibility and Transferability Inproceedings
In: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part II, pp. 3–18, Springer, 2019.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}