
Distributed Analytics
Over the past decade, vast amounts of machine-readable structured information have become available through the increasing popularity of semantic knowledge graphs in a variety of application domains. However, a major and yet unsolved challenge that research faces today is to perform scalable analytics, i.e. machine learning, inference and querying, of this knowledge while taking into account its rich semantic structures. Current analytics methods are, to our knowledge, either not fully aware of the semantics and structure of knowledge graphs or scale insufficiently.
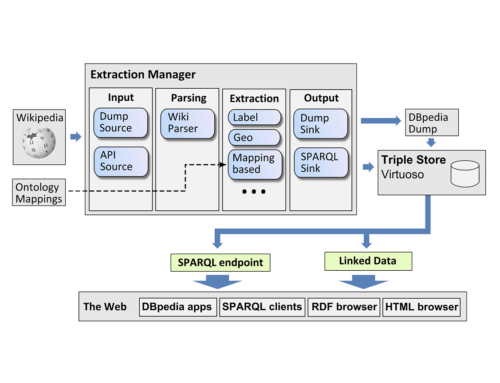
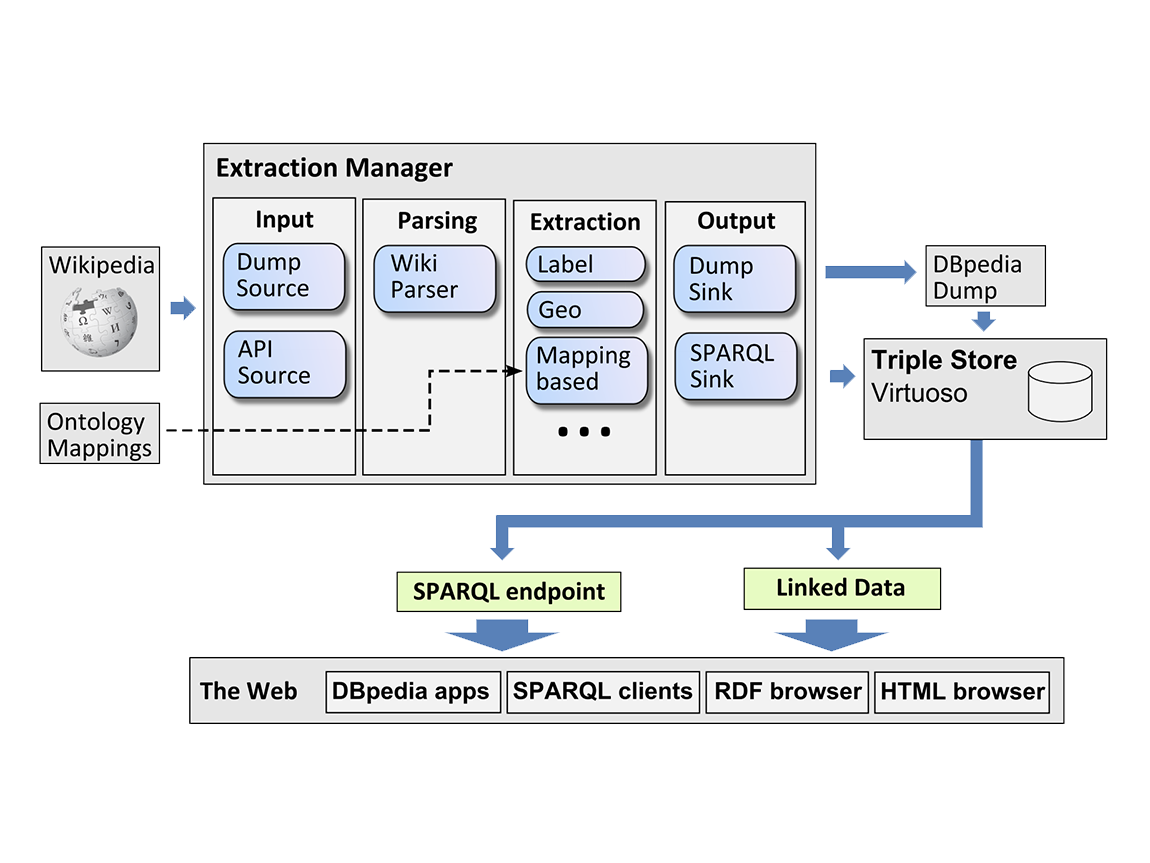
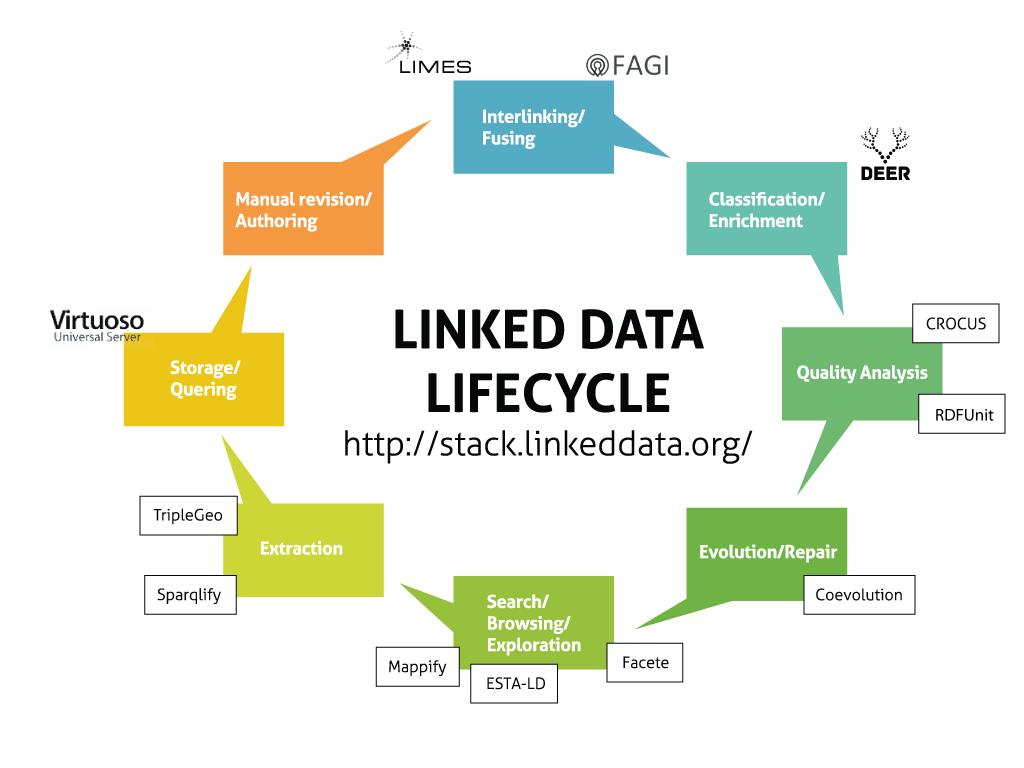
The aim of this research line, in particular our SANSA project, is to research whether this severe limitation can be overcome by jointly leveraging results from distributed analytics and semantic technologies. To achieve this, SANSA will advance the state of the art by developing foundational models and algorithms in (1) data distribution techniques for semantic knowledge graphs, (2) semantics-aware distributed computation of resource embeddings in knowledge graphs, (3) adaptive distributed querying, (4) efficient self-optimising inference execution plans and (5) distributed symbolic machine learning approaches. These advancements will be implemented as a semantic analytics stack which uses distributed in-memory computing models as the foundation and includes further layers for (1) knowledge distribution and representation, (2) querying and inference as well as (3) machine learning. By design, each layer will be both semantics aware and horizontally scalable.
The synthesis of the above advancements can enable powerful analytics which impact on several application areas, including life sciences (e.g. improved therapy response prediction), media and publishing (e.g. entity resolution and semantic querying) and the internet of things (e.g. smart meter optimisation, traffic pattern detection).
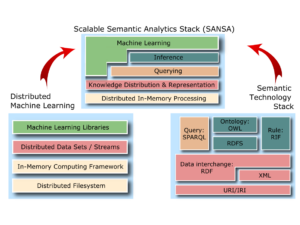
Scalable Semantic Analytics Stack (SANSA)
Related Publications
Inproceedings
DistSim - Scalable Distributed in-Memory Semantic Similarity Estimation for RDF Knowledge Graphs Inproceedings
In: 15th IEEE International Conference on Semantic Computing, ICSC 2021, Laguna Hills, CA, USA, January 27-29, 2021, pp. 333–336, IEEE, 2021.
A Scalable Approach for Distributed Reasoning over Large-scale OWL Datasets Inproceedings
In: Proceedings of the 13th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 2021, Volume 2: KEOD, Online Streaming, October 25-27, 2021, pp. 51–60, SCITEPRESS, 2021.
DistRDF2ML - Scalable Distributed In-Memory Machine Learning Pipelines for RDF Knowledge Graphs Inproceedings
In: CIKM '21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Queensland, Australia, November 1 - 5, 2021, pp. 4465–4474, ACM, 2021.
Literal2Feature: An Automatic Scalable RDF Graph Feature Extractor Inproceedings
In: Further with Knowledge Graphs - Proceedings of the 17th International Conference on Semantic Systems, SEMANTiCS, Amsterdam, The Netherlands, September 6-9, 2021, pp. 74–88, IOS Press, 2021.
A Distributed Approach for Parsing Large-scale OWL Datasets Inproceedings
In: Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 2020, Volume 2: KEOD, Budapest, Hungary, November 2-4, 2020, pp. 227–234, SCITEPRESS, 2020.
OWLStats: Distributed Computation of OWL Dataset Statistics Inproceedings
In: IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology, WI/IAT 2020, Melbourne, Australia, December 14-17, 2020, pp. 381–386, IEEE, 2020.
Clustering Pipelines of Large RDF POI Data Inproceedings
In: The Semantic Web: ESWC 2019 Satellite Events - ESWC 2019 Satellite Events, Portorož, Slovenia, June 2-6, 2019, Revised Selected Papers, pp. 24–27, Springer, 2019.
Towards a Scalable Semantic-Based Distributed Approach for SPARQL Query Evaluation Inproceedings
In: Semantic Systems. The Power of AI and Knowledge Graphs - 15th International Conference, SEMANTiCS 2019, Karlsruhe, Germany, September 9-12, 2019, Proceedings, pp. 295–309, Springer, 2019.
The Hubs and Authorities Transaction Network Analysis using the SANSA framework Inproceedings
In: Proceedings of the Posters and Demo Track of the 15th International Conference on Semantic Systems co-located with 15th International Conference on Semantic Systems (SEMANTiCS 2019), Karlsruhe, Germany, September 9th - to - 12th, 2019, CEUR-WS.org, 2019.
A Scalable Framework for Quality Assessment of RDF Datasets Inproceedings
In: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part II, pp. 261–276, Springer, 2019.
Sparklify: A Scalable Software Component for Efficient Evaluation of SPARQL Queries over Distributed RDF Datasets Inproceedings
In: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part II, pp. 293–308, Springer, 2019.
Querying Large-scale RDF Datasets Using the SANSA Framework Inproceedings
In: Proceedings of the ISWC 2019 Satellite Tracks (Posters & Demonstrations, Industry, and Outrageous Ideas) co-located with 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand, October 26-30, 2019, pp. 285–288, CEUR-WS.org, 2019.
Scalable Distributed Genetic Algorithm Using Apache Spark (S-GA) Inproceedings
In: Intelligent Computing Theories and Application - 15th International Conference, ICIC 2019, Nanchang, China, August 3-6, 2019, Proceedings, Part I, pp. 424–435, Springer, 2019.
Squerall: Virtual Ontology-Based Access to Heterogeneous and Large Data Sources Inproceedings
In: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part II, pp. 229–245, Springer, 2019.
Uniform Access to Multiform Data Lakes using Semantic Technologies Inproceedings
In: Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services, iiWAS 2019, Munich, Germany, December 2-4, 2019, pp. 313–322, ACM, 2019.
Divided We Stand Out! Forging Cohorts fOr Numeric Outlier Detection in Large Scale Knowledge Graphs (CONOD) Inproceedings
In: Knowledge Engineering and Knowledge Management - 21st International Conference, EKAW 2018, Nancy, France, November 12-16, 2018, Proceedings, pp. 534–548, Springer, 2018.
Profiting from Kitties on Ethereum: Leveraging Blockchain RDF with SANSA Inproceedings
In: Proceedings of the Posters and Demos Track of the 14th International Conference on Semantic Systems co-located with the 14th International Conference on Semantic Systems (SEMANTiCS 2018), Vienna, Austria, September 10-13, 2018, CEUR-WS.org, 2018.
SPIRIT: A Semantic Transparency and Compliance Stack Inproceedings
In: Proceedings of the Posters and Demos Track of the 14th International Conference on Semantic Systems co-located with the 14th International Conference on Semantic Systems (SEMANTiCS 2018), Vienna, Austria, September 10-13, 2018, CEUR-WS.org, 2018.
DistLODStats: Distributed Computation of RDF Dataset Statistics Inproceedings
In: The Semantic Web - ISWC 2018 - 17th International Semantic Web Conference, Monterey, CA, USA, October 8-12, 2018, Proceedings, Part II, pp. 206–222, Springer, 2018.
STATisfy Me: What Are My Stats? Inproceedings
In: Proceedings of the ISWC 2018 Posters & Demonstrations, Industry and Blue Sky Ideas Tracks co-located with 17th International Semantic Web Conference (ISWC 2018), Monterey, USA, October 8th - to - 12th, 2018, CEUR-WS.org, 2018.
Big Data Europe Inproceedings
In: Proceedings of the Workshops of the EDBT/ICDT 2017 Joint Conference (EDBT/ICDT 2017), Venice, Italy, March 21-24, 2017, CEUR-WS.org, 2017.
The BigDataEurope Platform - Supporting the Variety Dimension of Big Data Inproceedings
In: Web Engineering - 17th International Conference, ICWE 2017, Rome, Italy, June 5-8, 2017, Proceedings, pp. 41–59, Springer, 2017.
Managing Lifecycle of Big Data Applications Inproceedings
In: Knowledge Engineering and Semantic Web - 8th International Conference, KESW 2017, Szczecin, Poland, November 8-10, 2017, Proceedings, pp. 263–276, Springer, 2017.
The Tale of Sansa Spark Inproceedings
In: Proceedings of the ISWC 2017 Posters & Demonstrations and Industry Tracks co-located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 23rd - to - 25th, 2017, CEUR-WS.org, 2017.
Distributed Semantic Analytics Using the SANSA Stack Inproceedings
In: The Semantic Web - ISWC 2017 - 16th International Semantic Web Conference, Vienna, Austria, October 21-25, 2017, Proceedings, Part II, pp. 147–155, Springer, 2017.
Proceedings
Joint Proceedings of the 1st International Workshop on Knowledge Graph Building and 1st International Workshop on Large Scale RDF Analytics co-located with 16th Extended Semantic Web Conference (ESWC 2019), Portorož, Slovenia, June 3, 2019 Proceeding
CEUR-WS.org, 2489 , 2019.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}