
Extraction from Artificial Neural Networks
Overview
Artificial neural networks can be trained to perform excellently in many application areas. While they can learn from raw data to solve sophisticated recognition and analysis problems, the acquired knowledge remains hidden within the network architecture and is not readily accessible for analysis or further use: Trained networks are black boxes. Several research efforts therefore investigate the possibility to extract symbolic knowledge from trained networks, in order to analyze, validate, and reuse the structural insights gained implicitly during the training process.
In our research we have studied two directions:
The first direction is the extraction of propositional logic programs. We have found some foundational results and developed algorithms, which are correct and extract programs, which are as simple as possible — where simple is being understood in some clearly defined and meaningful way.
The second direction is the use of Inductive Logic Programming to perform the extraction task. The extraction task was reformulated as an ILP problem and a variety of different ILP programs were tested and the results evaluated.
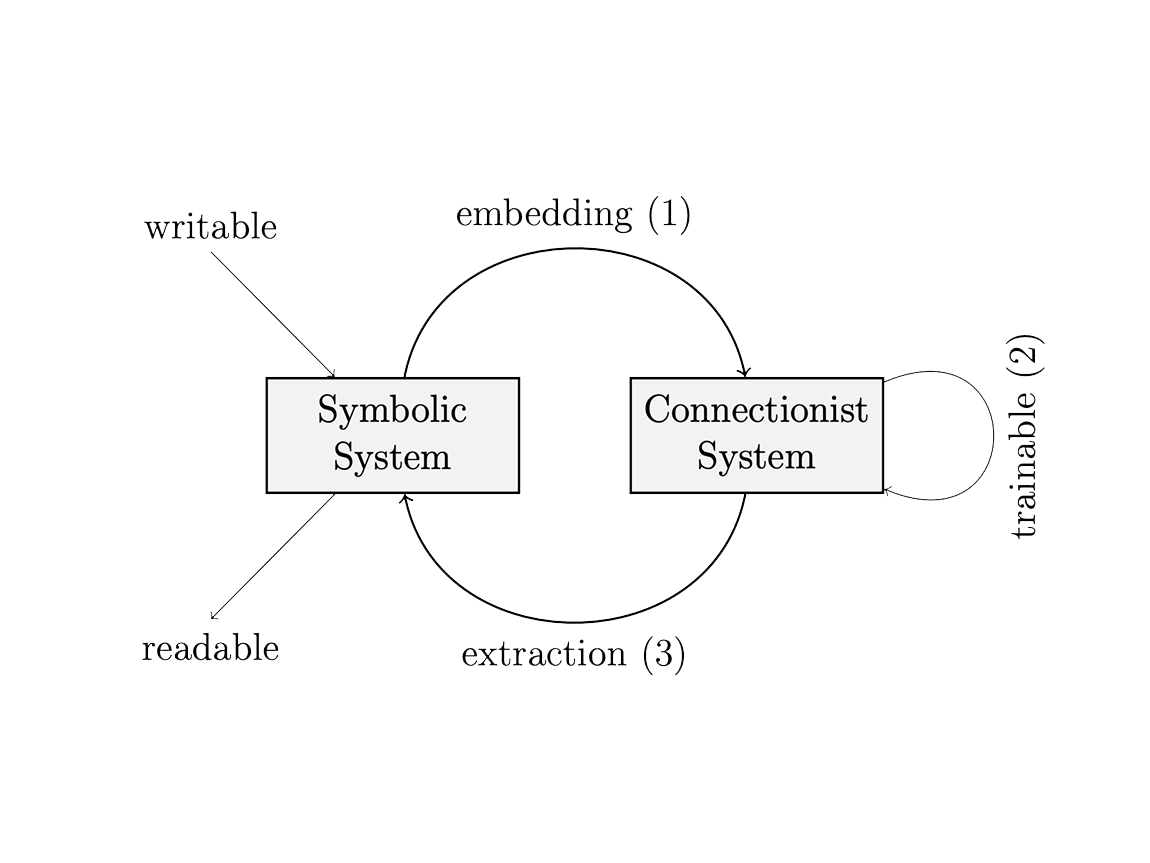
Figure: integration of symbolic and neural (connectionist) systems envision – this is from work in 2005 during my computer science studies (side note: not many people cared about the topic at that time)
Related Publications
Journal Articles
Extracting reduced logic programs from artificial neural networks Journal Article
In: Appl. Intell., 32 (3), pp. 249–266, 2010.
Informal Publications
Extracting Logic Programs from Artificial Neural Networks Informal Publications
2005, ("Großer Beleg", supervisors: Dr. Pascal Hitzler, Dipl. Inf. Sebastian Bader, Prof. Steffen Hölldobler).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}