
Question Answering over Knowledge Graphs
Since around 2011, I work on question answering over knowledge graphs (KGQA). In a narrow sense question answering over knowledge graphs is the task of translating a natural language question into a formal query (often SPARQL). Question answering has many interesting applications, e.g., in call centres, production systems, the automotive sector, home entertainment and smart assistants.
You can have a look at our introduction to neural question answering over knowledge graphs to find out more about the field if you are interested. I pursue the development of two classes of methods in this field:
1.) The first class of methods is based on “traditional” natural language processing (NLP) pipelines, which translate the natural language query via a sequence of steps into an intermediate form.

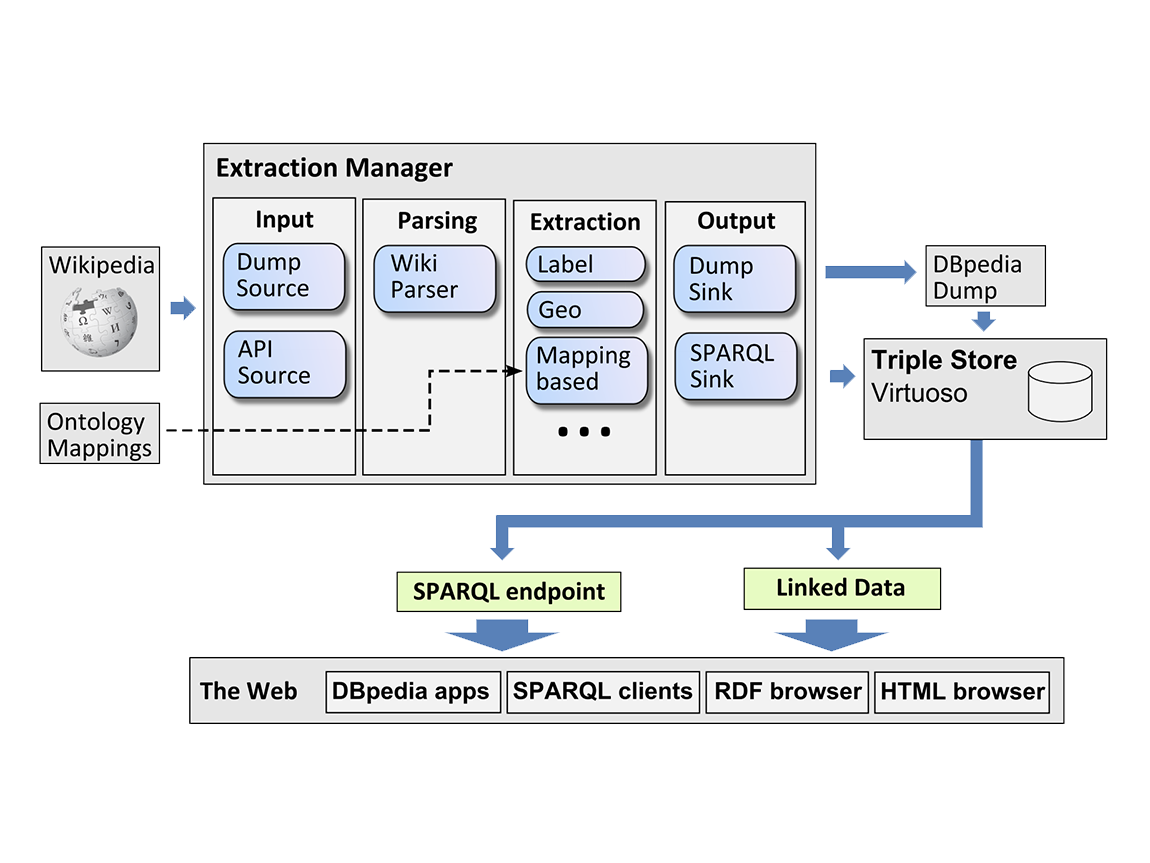
Figure: Typical KGQA processing pipeline starting from the input question (left) to the detection of entities and relation (= shallow parsing), linking to the knowledge graph and finally query building. Often, the answer is then verbalised and returned to the user. (The typo “Barak” is intentional.)
This intermediate form is then converted into a formal query. In initial work (published at WWW 2012), we translated natural language input into a first order logic representation that was subsequently aligned with the actual knowledge graph. This can be combined with active supervised machine learning for capturing user feedback as we have shown previously (ESWC 2011). Later, we used a normalised query structure to be more robust against different paraphrases of the same underlying query (ESWC 2016). We also improved the state of the art in individual steps of typical QA pipelines. For example in the EARL approach (ISWC 2018), we perform joint entity and relation linking of the question into by casting the task into a generalised traveling salesman problem (GTSP) on the so called subdivision graph. This way, we can use existing GTSP solver, which can then derive an optimal (w.r.t. the problem formulation) solution when there are multiple candidates for entities and relations in the question. In later work, we developed a deep reinforcement learning approach for shallow parsing that can work with a delayed reward signal from the linker. Since this approach can be fine-tuned towards question (rather than generic text), coarse-grained annotations (compared to POS taggers) and the specific knowledge graph, it achieved state-of-the-art performance in the LCQuAD and QALD7 benchmarks. We are also working on pipeline composition (WWW 2018) which allows researchers to focus on specific components as the pipeline orchestration is performed dynamically.
2.) The second class of methods are “end-to-end” systems solving the KGQA task in a single step. A core idea underlying this theme of research is to avoid the error propagation of pipeline approaches and, therefore, overall higher accuracy and robustness of question answering. Despite not being able to profit from several decades of research in natural language processing, this class of methods has recently led to state-of-the-art results when sufficient training data is available. A relatively early example of this is an approach, in which we explored neural networks with word and character-level embeddings (WebConf 2017), which was at the time the most accurate end-to-end question answering system for the Facebook AI simple questions benchmark (even though it’s quite simple from today’s point of view). In a nutshell, both the natural language question as well as the nodes (entities) and edges (called predicate here) in the knowledge graph were encoded and a similarity function applied:
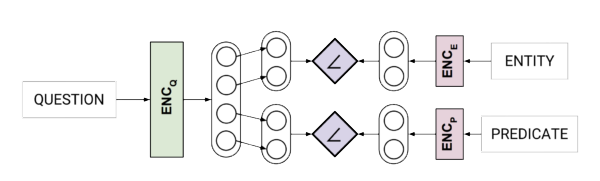
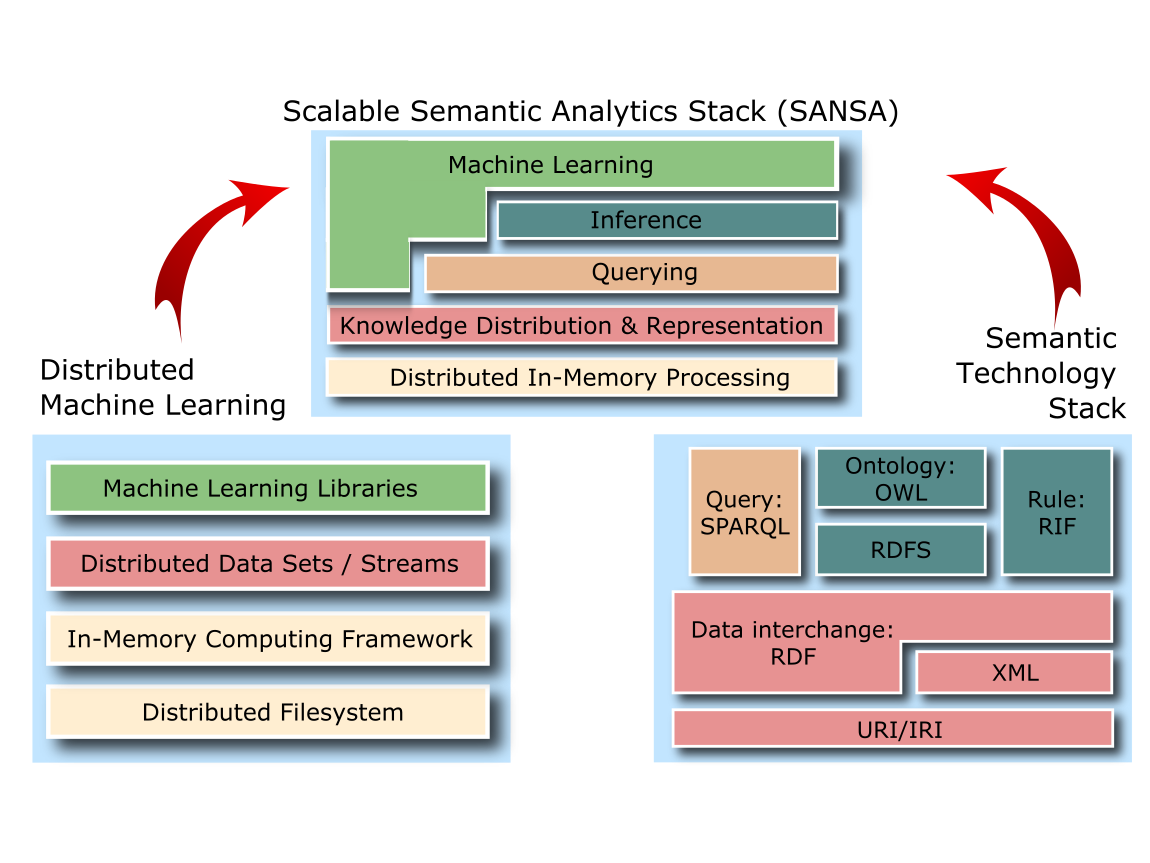
Figure: Neural End-to-end KGQA system architecture allowing to answer simple questions with a single entity and predicate
In 2018, we developed a sequence-to-sequence translation-based approach using neural networks, that is able to generate more complex queries and was at the time the state-of-the-art algorithm for the WikiSQL benchmark for learning SQL queries over relational tables. More recently, we used graph attention networks and Transformer architectures to enable conversational QA scenarios via a multi-task semantic parsing approach. This is currently (as of 2021) the state-of-the-art approach for complexing sequential question answering and has substantially improved the accuracy compared to baselines on the CSQA (Complex Sequential Question Answering) dataset published by Saha et. al.
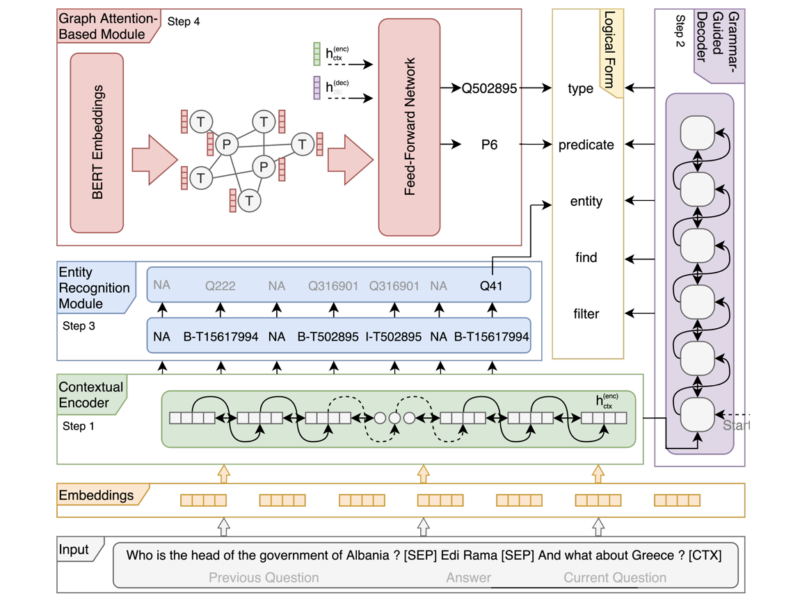
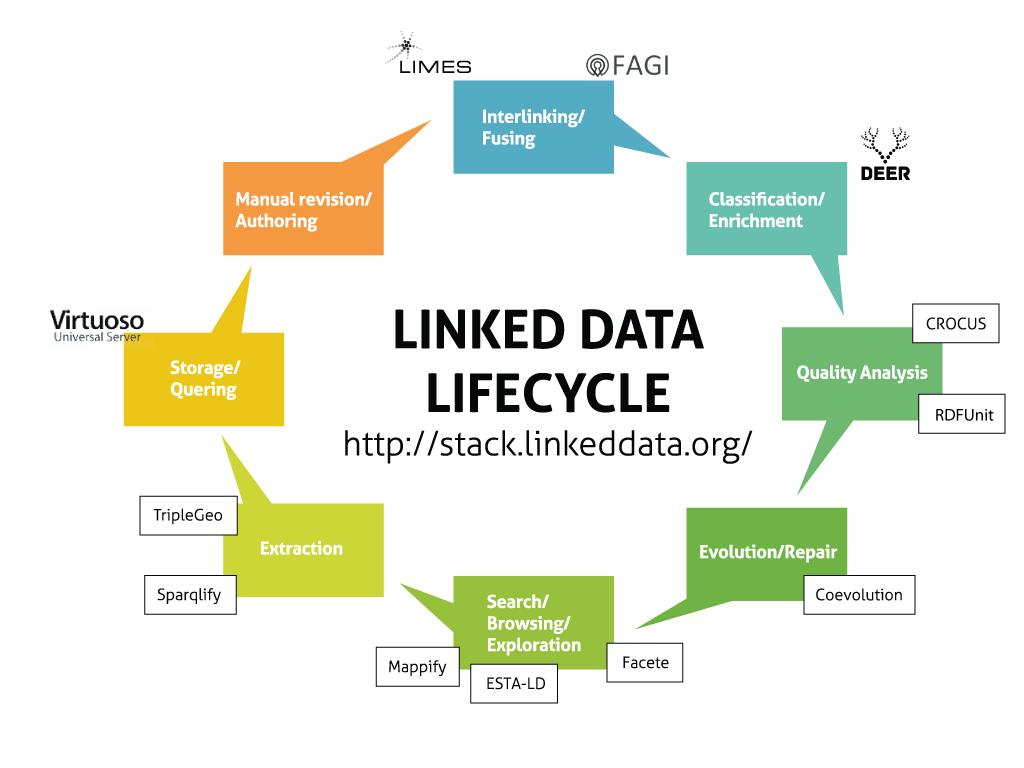
Figure: Multi-task Semantic Parsing with Transformer and Graph Attention Networks architecture. It consists of three modules: 1) A semantic parsing-based transformer model, containing a contextual encoder and a grammar guided decoder. 2) An entity recognition module, which identifies all the entities in the context, together with their types, linking them to the knowledge graph. It filters them based on the context and permutes them, in case of more than one required entity. Finally, 3) a graph attention-based module that uses a GAT network initialised with BERT embeddings to incorporate and exploit correlations between (entity) types and predicates. The resulting node embeddings, together with the context hidden state (hctx) and decoder hidden state (dh), are used to score the nodes and predict the corresponding type and predicate.
Related Publications
Journal Articles
Tree-KGQA: An Unsupervised Approach for Question Answering Over Knowledge Graphs Journal Article
In: IEEE Access, 10 , pp. 50467–50478, 2022.
SGPT: A Generative Approach for SPARQL Query Generation From Natural Language Questions Journal Article
In: IEEE Access, 10 , pp. 70712–70723, 2022.
Survey on English Entity Linking on Wikidata: Datasets and approaches Journal Article
In: Semantic Web, 13 (6), pp. 925–966, 2022.
Introduction to neural network-based question answering over knowledge graphs Journal Article
In: Wiley Interdiscip. Rev. Data Min. Knowl. Discov., 11 (3), 2021.
IQA: Interactive query construction in semantic question answering systems Journal Article
In: Journal of Web Semantics, 64 , pp. 100586, 2020.
No one is perfect: Analysing the performance of question answering components over the DBpedia knowledge graph Journal Article
In: Journal of Web Semantics, 65 , pp. 100594, 2020.
Survey on challenges of Question Answering in the Semantic Web Journal Article
In: Semantic Web, 8 (6), pp. 895–920, 2017.
Inproceedings
Contrastive Representation Learning for Conversational Question Answering over Knowledge Graphs Inproceedings
In: Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, October 17-21, 2022, pp. 925–934, ACM, 2022.
CHOLAN: A Modular Approach for Neural Entity Linking on Wikipedia and Wikidata Inproceedings
In: Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021, pp. 504–514, Association for Computational Linguistics, 2021.
Context Transformer with Stacked Pointer Networks for Conversational Question Answering over Knowledge Graphs Inproceedings
In: The Semantic Web - 18th International Conference, ESWC 2021, Virtual Event, June 6-10, 2021, Proceedings, pp. 356–371, Springer, 2021.
Conversational Question Answering over Knowledge Graphs with Transformer and Graph Attention Networks Inproceedings
In: Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, April 19 - 23, 2021, pp. 850–862, Association for Computational Linguistics, 2021.
ParaQA: A Question Answering Dataset with Paraphrase Responses for Single-Turn Conversation Inproceedings
In: The Semantic Web - 18th International Conference, ESWC 2021, Virtual Event, June 6-10, 2021, Proceedings, pp. 598–613, Springer, 2021.
VOGUE: Answer Verbalization Through Multi-Task Learning Inproceedings
In: Machine Learning and Knowledge Discovery in Databases. Research Track - European Conference, ECML PKDD 2021, Bilbao, Spain, September 13-17, 2021, Proceedings, Part III, pp. 563–579, Springer, 2021.
VQuAnDa: Verbalization QUestion ANswering DAtaset Inproceedings
In: The Semantic Web - 17th International Conference, ESWC 2020, Heraklion, Crete, Greece, May 31-June 4, 2020, Proceedings, pp. 531–547, Springer, 2020.
CASQAD - A New Dataset for Context-Aware Spatial Question Answering Inproceedings
In: The Semantic Web - ISWC 2020 - 19th International Semantic Web Conference, Athens, Greece, November 2-6, 2020, Proceedings, Part II, pp. 3–17, Springer, 2020.
Distantly Supervised Question Parsing Inproceedings
In: ECAI 2020 - 24th European Conference on Artificial Intelligence, 29 August-8 September 2020, Santiago de Compostela, Spain, August 29 - September 8, 2020 - Including 10th Conference on Prestigious Applications of Artificial Intelligence (PAIS 2020), pp. 2290–2297, IOS Press, 2020.
PNEL: Pointer Network Based End-To-End Entity Linking over Knowledge Graphs Inproceedings
In: The Semantic Web - ISWC 2020 - 19th International Semantic Web Conference, Athens, Greece, November 2-6, 2020, Proceedings, Part I, pp. 21–38, Springer, 2020.
Old is Gold: Linguistic Driven Approach for Entity and Relation Linking of Short Text Inproceedings
In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pp. 2336–2346, Association for Computational Linguistics, 2019.
LC-QuAD 2.0: A Large Dataset for Complex Question Answering over Wikidata and DBpedia Inproceedings
In: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part II, pp. 69–78, Springer, 2019.
QaldGen: Towards Microbenchmarking of Question Answering Systems over Knowledge Graphs Inproceedings
In: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part II, pp. 277–292, Springer, 2019.
Pretrained Transformers for Simple Question Answering over Knowledge Graphs Inproceedings
In: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part I, pp. 470–486, Springer, 2019.
Learning to Rank Query Graphs for Complex Question Answering over Knowledge Graphs Inproceedings
In: The Semantic Web - ISWC 2019 - 18th International Semantic Web Conference, Auckland, New Zealand, October 26-30, 2019, Proceedings, Part I, pp. 487–504, Springer, 2019.
Complex Query Augmentation for Question Answering over Knowledge Graphs Inproceedings
In: On the Move to Meaningful Internet Systems: OTM 2019 Conferences - Confederated International Conferences: CoopIS, ODBASE, C&TC 2019, Rhodes, Greece, October 21-25, 2019, Proceedings, pp. 571–587, Springer, 2019.
Microbenchmarks for Question Answering Systems Using QaldGen Inproceedings
In: Proceedings of the ISWC 2019 Satellite Tracks (Posters & Demonstrations, Industry, and Outrageous Ideas) co-located with 18th International Semantic Web Conference (ISWC 2019), Auckland, New Zealand, October 26-30, 2019, pp. 261–264, CEUR-WS.org, 2019.
Formal Query Generation for Question Answering over Knowledge Bases Inproceedings
In: The Semantic Web - 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3-7, 2018, Proceedings, pp. 714–728, Springer, 2018.
A Question Answering System on Regulatory Documents Inproceedings
In: Legal Knowledge and Information Systems - JURIX 2018: The Thirty-first Annual Conference, Groningen, The Netherlands, 12-14 December 2018, pp. 41–50, IOS Press, 2018.
Deep Query Ranking for Question Answering over Knowledge Bases Inproceedings
In: Machine Learning and Knowledge Discovery in Databases - European Conference, ECML PKDD 2018, Dublin, Ireland, September 10-14, 2018, Proceedings, Part III, pp. 635–638, Springer, 2018.
Joint Entity and Relation Linking Using EARL Inproceedings
In: Proceedings of the ISWC 2018 Posters & Demonstrations, Industry and Blue Sky Ideas Tracks co-located with 17th International Semantic Web Conference (ISWC 2018), Monterey, USA, October 8th - to - 12th, 2018, CEUR-WS.org, 2018.
EARL: Joint Entity and Relation Linking for Question Answering over Knowledge Graphs Inproceedings
In: The Semantic Web - ISWC 2018 - 17th International Semantic Web Conference, Monterey, CA, USA, October 8-12, 2018, Proceedings, Part I, pp. 108–126, Springer, 2018.
Why Reinvent the Wheel: Let's Build Question Answering Systems Together Inproceedings
In: Proceedings of the 2018 World Wide Web Conference on World Wide Web, WWW 2018, Lyon, France, April 23-27, 2018, pp. 1247–1256, ACM, 2018.
Named Entity Recognition in Twitter Using Images and Text Inproceedings
In: Current Trends in Web Engineering - ICWE 2017 International Workshops, Liquid Multi-Device Software and EnWoT, practi-O-web, NLPIT, SoWeMine, Rome, Italy, June 5-8, 2017, Revised Selected Papers, pp. 191–199, Springer, 2017.
How to Revert Question Answering on Knowledge Graphs Inproceedings
In: Proceedings of the ISWC 2017 Posters & Demonstrations and Industry Tracks co-located with 16th International Semantic Web Conference (ISWC 2017), Vienna, Austria, October 23rd - to - 25th, 2017, CEUR-WS.org, 2017.
LC-QuAD: A Corpus for Complex Question Answering over Knowledge Graphs Inproceedings
In: The Semantic Web - ISWC 2017 - 16th International Semantic Web Conference, Vienna, Austria, October 21-25, 2017, Proceedings, Part II, pp. 210–218, Springer, 2017.
Neural Network-based Question Answering over Knowledge Graphs on Word and Character Level Inproceedings
In: Proceedings of the 26th International Conference on World Wide Web, WWW 2017, Perth, Australia, April 3-7, 2017, pp. 1211–1220, ACM, 2017.
AskNow: A Framework for Natural Language Query Formalization in SPARQL Inproceedings
In: The Semantic Web. Latest Advances and New Domains - 13th International Conference, ESWC 2016, Heraklion, Crete, Greece, May 29 - June 2, 2016, Proceedings, pp. 300–316, Springer, 2016.
Exploring Term Networks for Semantic Search over RDF Knowledge Graphs Inproceedings
In: Metadata and Semantics Research - 10th International Conference, MTSR 2016, Göttingen, Germany, November 22-25, 2016, Proceedings, pp. 249–261, 2016.
CubeQA - Question Answering on RDF Data Cubes Inproceedings
In: The Semantic Web - ISWC 2016 - 15th International Semantic Web Conference, Kobe, Japan, October 17-21, 2016, Proceedings, Part I, pp. 325–340, 2016.
An Open Question Answering Framework Inproceedings
In: Proceedings of the ISWC 2015 Posters & Demonstrations Track co-located with the 14th International Semantic Web Conference (ISWC-2015), Bethlehem, PA, USA, October 11, 2015, CEUR-WS.org, 2015.
Towards an open question answering architecture Inproceedings
In: Proceedings of the 10th International Conference on Semantic Systems, SEMANTICS 2014, Leipzig, Germany, September 4-5, 2014, pp. 57–60, ACM, 2014.
Towards question answering on statistical linked data Inproceedings
In: Proceedings of the 10th International Conference on Semantic Systems, SEMANTICS 2014, Leipzig, Germany, September 4-5, 2014, pp. 61–64, ACM, 2014.
SPARQL2NL: verbalizing sparql queries Inproceedings
In: 22nd International World Wide Web Conference, WWW '13, Rio de Janeiro, Brazil, May 13-17, 2013, Companion Volume, pp. 329–332, International World Wide Web Conferences Steering Committee / ACM, 2013.
User Interface for a Template Based Question Answering System Inproceedings
In: Knowledge Engineering and the Semantic Web - 4th International Conference, KESW 2013, St. Petersburg, Russia, October 7-9, 2013. Proceedings, pp. 258–264, Springer, 2013.
deqa: Deep Web Extraction for Question Answering Inproceedings
In: The Semantic Web - ISWC 2012 - 11th International Semantic Web Conference, Boston, MA, USA, November 11-15, 2012, Proceedings, Part II, pp. 131–147, Springer, 2012.
Template-based question answering over RDF data Inproceedings
In: Proceedings of the 21st World Wide Web Conference 2012, WWW 2012, Lyon, France, April 16-20, 2012, pp. 639–648, ACM, 2012.
AutoSPARQL: Let Users Query Your Knowledge Base Inproceedings
In: The Semantic Web: Research and Applications - 8th Extended Semantic Web Conference, ESWC 2011, Heraklion, Crete, Greece, May 29-June 2, 2011, Proceedings, Part I, pp. 63–79, Springer, 2011.
Proceedings
Proceedings of the SeMantic AnsweR Type prediction task (SMART) at ISWC 2020 Semantic Web Challenge co-located with the 19th International Semantic Web Conference (ISWC 2020), Virtual Conference, November 5th, 2020 Proceeding
CEUR-WS.org, 2774 , 2020.
Informal Publications
Using Multi-Label Classification for Improved Question Answering Informal Publications
2017.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}