

Neural Language Models – A Path to Artificial General Intelligence or a Blind Alley?
[Disclaimer: The text below represents a personal opinion based on the scientific evidence we have so far.]
With the rapid progress AI research has made over the past years, the decades-old question of whether machines can achieve a form of general intelligence has regained a lot of interest. One particular technology that has played a major role in those discussions are (neural) language models. In essence, a language model tries to model the distribution of all possible utterances in a particular language. They are often trained on simple tasks, such as predicting the next word in a sentence or finding a missing word in a sentence – but this is done at an extreme scale using very large neural networks. Language models have a wide range of applications in speech recognition, dialogue systems, machine translation and information retrieval. With the advent of recent very large-scale Transformer-based language models like GPT-3, Switch Transformers or Wu Dao 2.0, which achieved impressive results in a variety of applications, a key question is whether those neural language models (NLMs) are potential building blocks for artificial general intelligence.
Few-Shot Learning and General Intelligence
One particularly interesting aspect in this discussion is the few-shot learning capability of GPT-3 and other language models: they only need a few examples in order to perform a new language-related task. This capability of learning quickly from a few examples rather than needing several thousand training examples is an important goal in AI. Moreover, this type of intelligence is more “general” in the sense that a single model can be used in potentially thousands or even millions of use cases and domains without requiring specific architecture modifications, retraining or fine-tuning. This is similar to humans – who often require only a few examples to learn a new task.
This is great, but does this automatically make large-scale language models the key technology for artificial general intelligence (AGI)? Opinions on this vary greatly. Here are two (seemingly) contrasting views on this matter:
“… the problem is not with GPT-3’s syntax (which is perfectly fluent) but with its semantics: it can produce words in perfect English, but it has only the dimmest sense of what those words mean, and no sense whatsoever about how those words relate to the world.”
— Gary Marcus and Ernest Davies (source)
“Wu Dao 2.0 aims to enable machines to think like humans and achieve cognitive abilities beyond the Turing test.”
— Tang Jie, lead researcher behind Wu Dao 2.0 (source)
In order to analyse whether NLMs are an important building block for general intelligence, I believe (at least) two aspects are critical:
1. Are large-scale language models only memorizing training data or do they possess actual learning/generalisation capabilities?
2. Can we overcome the data labelling dilemma, i.e. the fact that we rely on huge amounts of text for unsupervised training but still want to keep some control over what the resulting model does? (e.g. avoidance of unwanted bias, knowledge inception)
I’ll discuss both points below. After that, I will address the practical concern that many researchers are locked out from even investigating those questions due to the sheer size and restricted availability of NLMs.
Memorisation vs. Generalisation
Given that large-scale neural language models have an extremely high number of parameters, a natural question is whether they just memorize input data or can actually combine several pieces of evidence. In simpler terms, the question is: Are neural language models actually intelligent?
To answer this, we should first have a look at where they perform well and where they don’t. Using GPT-3 as an example, it is evident that the model doesn’t automatically perform well in all types of tasks out of the box. In the benchmarks in the original paper, GPT-3 performs far below the state-of-the-art in several tasks, such as commonsense reasoning, summary generation, translation and machine reading comprehension, while it does very well at other tasks involving text generation. However, this alone does not allow to answer the question since GPT-3 had no task-specific training data. This means it cannot exploit dataset-specific patterns in the same way as task-specific approaches. One could argue that its performance on those tasks is, therefore, underrated as it cannot use spurious patterns in the data that are no sign of intelligence. For example, the performance of better performing machine reading comprehension models can break down under simple text changes.
This means we need to dive a bit deeper into specific scenarios:
One interesting copycat test was done by Prof. Mitchell and involves finding analogies, e.g. using the following prompt:
Q: If a b c changes to a b d, what does p q r change to?
A: p q s
Q: If a b c changes to a b d, what does i j k change to?
GPT-3 answered “i j l” here, so it correctly changed the last symbol to the next letter in the alphabet. This is pretty good and, moreover, it also succeeded at some other, more difficult tasks. (Note: The model did not see those examples before.) However, it was not doing well in zero-shot learning – in the above example, it could not solve the task after only getting the first question. In the tests, GPT-3 also had some errors, which are not typical for humans. How one rates the NLM performance on this depends pretty much on what the expectations are. Having a relatively low expectation of any true understanding of an NLM, I rated the results positively. It seems that language models do have generalisation capabilities, but there are also clear limitations. For example, GPT-3 does not learn to reverse sentences or assigns similar chances to sheep being black or white. One should, however, also point out that those tasks actually go beyond modelling (mostly English) language. For example, in the above copycat example, one could argue that a child who speaks English fluently and natively, might still struggle at this task. In contrast, an adult who does not speak English fluently could still solve the task. This raises the question of what we should expect from a language model. I would argue that a language model trained only on plain text is unlikely to be an AGI itself, but can rather be a (potentially very useful) component helping to build AGI capabilities.
What about other large NLMs? There isn’t too much information available on Wu Dao 2.0, which is an order of magnitude larger than GPT-3. It has supposedly surpassed GPT-3 performance on the SuperGLUE benchmark and is trained on different modalities (audio, text, images), so one could assume its capabilities to be beyond GPT-3 However, not much external verification has been conducted and, to my understanding, the model is currently not accessible outside of its partner network.
Overall, NLMs do generalise and it is in some sense remarkable how far simple word correlation takes you. However, the jury is still open as to whether it can also be trained to understand causal relationships, which Bengio or Schölkopf recognise as a major next AI challenge towards generalisation.
The Data Labeling Dilemma (aka the “NLM Control Problem”)
Unsupervised learning is considered to be a key ingredient to research towards AGI as labelled data is often very time-consuming and expensive to obtain. Unsupervised pre-training has been highly beneficial as the results across several domains and tasks in NLP over the past years have shown.
However, this leads to a key problem: While an abundant amount of text is available for unsupervised pre-training, any model using those large volumes of text also inherits the statistical correlations and patterns in such texts. The dilemma is that learning this kind of correlation is exactly what most language models are trained to do. As is usually the case in AI (and computer science in general), you get exactly what you specified. This means that any unintended bias, including swear words, discriminating language etc. will therefore be contained in the language model. From my point of view, this is a special case of the general AI Control Problem, i.e. the issue of building a potentially superintelligent system that can inadvertently cause harm to us humans. I will therefore call this the “NLM Control Problem” here. This is a problem for most practical use cases, in which organisations need to keep some level of control over what their NLP systems are doing.
The NLM Control Problem is most frequently analysed in the context of unintended bias and recently OpenAI itself has published a process to improve language model behaviour by using only a small curated dataset. While those and other results are promising, the NLM Control Problem goes beyond the avoidance of unintended bias: I believe we need more general methods for inspecting, removing, updating and injecting knowledge into language models. Most organisations using neural language models may be impressed by the out-of-the-box performance in a few-shot learning setting, but then run against a wall when trying to optimise the model and adapt it to their specific use cases (see this paper). Moreover, a common scenario is that the model should connect knowledge graphs or any other forms of structured knowledge as a form of “ground truth” from which answers can be derived. Phrased more generally:
“We must refocus, working towards developing a framework for building systems that can routinely acquire, represent, and manipulate abstract knowledge, using that knowledge in the service of building, updating, and reasoning over complex, internal models of the external world.”
— Gary Marcus in “The Next Decade in AI”
There have been multiple approaches to address this issue and I believe knowledge grounding, inspection and extraction will be crucially important to the future of neural language models. Without some form of grounding and only relying on correlation, it is very difficult for NLMs to go beyond a shallow understanding of the text they process. It is clear that the issues discussed so far still need a lot of research to be carried out. However, are we really able to progress significantly in those areas when most of us do not have access to very large-scale neural language models? That’s what I will discuss next.
Are most researchers locked out from investigating large-scale neural language models?
It is well known that the hardware resources required for building large-scale neural LMs are huge. GPT-3 was trained on the OpenAI supercomputer with 10.000 GPUs and a single training run costs millions of dollars. Moreover, GPT-3 is exclusively licensed by Microsoft and access to the model requires requests, which do not necessarily need to be accepted by OpenAI. Access to Wu Dao 2.0 is also not available for all researchers. This means that most researchers need to experiment with small and medium scale NLMs. However, this is insufficient – after all, a core message of the original GPT-3 paper was that the scale of the model influences the results significantly (more on this below). Leaving such an important area of research, which will potentially influence the lives of millions (if not billions) of people, to a few organisations and countries, poses a risk not only for AI research but for society at large.
What can be done to overcome those issues? One direction is to work with smaller-scale models with similar performance or characteristics. For example, a recent interesting paper has investigated the few-shot learning capabilities of small-scale NLMs. Another direction is to use more efficient or specialised hardware. This is likely to play a major role in training future NLMs. However, I believe that despite those efforts, it won’t be possible for most researchers to access and use the most competitive language models (see also this post from my colleague Kristian Kersting). To overcome this, there are important initiatives like BigScience, which bring many researchers together. My own team will play a major role in a newly acquired project called “OpenGPT-X”, which will make large-scale NLMs available to all researchers based on the GAIA-X infrastructure (blatant self-advertisement: we are hiring and if you want to work in OpenGPT-X, please apply here). OpenGPT-X will start at the end of 2021 and run for 3 years. Further initiatives will be needed around the globe to make NLMs more accessible and support a broad range of languages.
What can we expect in the future?
All the above is particularly important, because we may need even larger neural language models in the future: The research results so far show that their limitations haven’t been reached as shown in the figure below. In other words: even bigger neural language models are very likely to produce even better results. Even the 175 billion parameters of GPT-3 are still lower than the number of synapses in the human brain which contains more than 125 trillion synapses just in the cerebral cortex alone. Will there be limitations? Naturally, our own understanding capabilities will be a barrier: The input texts for NLMs are (largely) produced by humans such that a human-level understanding of language will also mark a boundary at which further scaling up the models does not yield further improvements. However, we will not know much about the exact limitations and boundaries until we actually try.
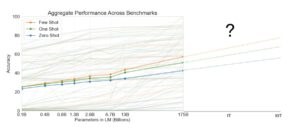
( source adapted from the original GPT-3 Paper )
Progress is made along this dimension: Earlier this year, Switch Transformers have already surpassed the trillion parameter mark at (relatively) low computational cost. In May 2021, Google has presented LaMDA in their annual I/O conference, which has specifically showcased the use of very large language models for chatbots. Wu Dao 2.0 was released in June this year and has ten times the size of GPT-3 with overall 1.75 trillion parameters. It uses both text and image data and achieved state-of-the-art performance across a wide range of tasks. It is almost certain that the scale of models will increase further – while hopefully not locking out large parts of the NLP community from investigating and improving the capabilities of such models.
Concluding Thoughts
What is the final takeaway on the question raised in the title of this post? As of now, it is still open whether large-scale neural LMs will be a substantial building block for AGI. The evidence so far indicates that they are not a blind alley and a rather interesting research field in which the limits haven’t been fully explored. However, I believe they are unlikely to yield further breakthroughs when used standalone, i.e. only pre-training on simple word prediction tasks using large amounts of text is not enough – combinations with other forms of knowledge are promising. As pointed out above, from my perspective deeper investigations into the generalisation capabilities of such models and the NLM Control Problem are necessary. This will require substantial research activities and that is why it is crucially important to not limit those activities to the research labs of a limited number of companies worldwide, but rather activate the NLP research community at large.
One Comment
Comments are closed.


{kind=link}
{kind=link}
{kind=link}
Helpful information. Fortunate me I found your site unintentionally, and I’m
shocked why this coincidence did not happened earlier!
I bookmarked it.