
Beyond Boundaries: A Human-like Approach for Question Answering over Structured and Unstructured Information Sources
Together with my co-authors, we are excited to share our work on an easy-to-apply method to improve LLM reasoning and how we applied it for question answering across heterogeneous sources. 🚀
Language models relying solely on their internal parameters lack knowledge about recent knowledge as well as less common knowledge (see e.g. this paper). It is also challenging to directly update LLMs and trace their responses to specific sources. To address this, research has focused on enhancing these models with the capability to access external information sources (often via retrieval-augmented generation – RAG). External sources can be structured, like knowledge graphs, which usually offer high precision and the ability to handle complex queries, or unstructured, like text corpora, which often provide a broader range of information. We propose a prompting method allowing LLMs to analyse both structured and unstructured external knowledge and combine this with their parametric knowledge.
First, let’s start with the results:
Our method, “HumanIQ” (Human-like Intelligent Queries) can be used on top of a base LLM to improve its capability to follow reasoning processes using the Google ReAct pattern. HumanIQ itself is not task-dependent, but we were particularly interested in diving deep into question answering from structured and unstructured information systems. In the LLM version of this task, the goal is to combine parametric LLM knowledge, structured knowledge, e.g. from a knowledge graph and unstructured knowledge, e.g. from text corpora, to best answer questions.
We tested five systems:
- 3 vanilla LLMs: MPT-30B, GPT-3.5 and GPT-4
- 2 systems “HQA-GPT-3.5” and “HQA-GPT-4” combining HumanIQ for hybrid question answering (=HQA) with GPT-3.5 and GPT-4 as base LLMs respectively
We used Wikidata and Wikipedia as information sources. For our experiments, we employed random subsets of three different question answering datasets – Mintaka, QALD and CompMix – all of which we consider to be of high quality. The datasets contain pairs of questions (like “Which player scored most goals in the UEFA Euro 2004?”) and answers (“Milan Baroš scored the most goals at the Euro 2004 with overall 5 goals”).
Given that automatic metrics were not reliable, we checked the correctness of answers across the datasets manually and obtained the following results:
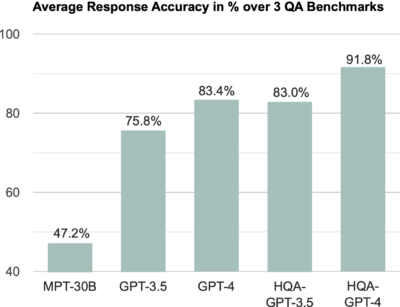
So, for the 550 questions that we checked, applying Human-IQ could cut the error rate of GPT-4 (16.6%) by half (8.2%)!
As a next step, we wanted to see which answers are preferred by users – being correct is also important for human preference, but beyond this, answers should also be informative, well-written, engaging and not unnecessarily verbose. To test this, we did a blind preference learning experiment in which external annotators get inputs from two systems for a given question and then must decide which is better. These are the results we obtained for comparing our best system, “HQA-GPT-4”, against other systems:
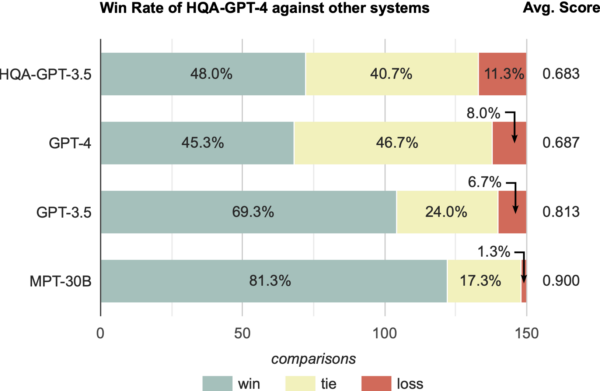
The average score on the right is obtained by rating a win as 1 point, a tie as 0.5 points, and a loss as 0 points and averaging this across all questions. A score of 0.687 indicates a strong preference for the system over the base GPT-4 model. One factor for this is that our system could often provide a more engaging and truthful response based on the retrieved content. While GPT-4 generally also performs very well and answers many questions correctly, it did tend to introduce hallucinations in auxiliary facts provided along with the answer.
How does the method work?
First, we collect solution processes for a given task—in this case, question answering—from humans. Solution processes describe how external tools (APIs) and thoughts in natural language can be combined to solve a task. We did this in two workshop sessions: In the first workshop, the participants could decide which tools are most suitable (e.g., searching Wikipedia, answering a question by reading particular Wikipedia pages, linking Wikipedia pages to Wikidata entities, queries over Wikidata). Participants could use those tools in the second workshop to solve randomly selected tasks. HumanIQ comes with a user interface that supports this.
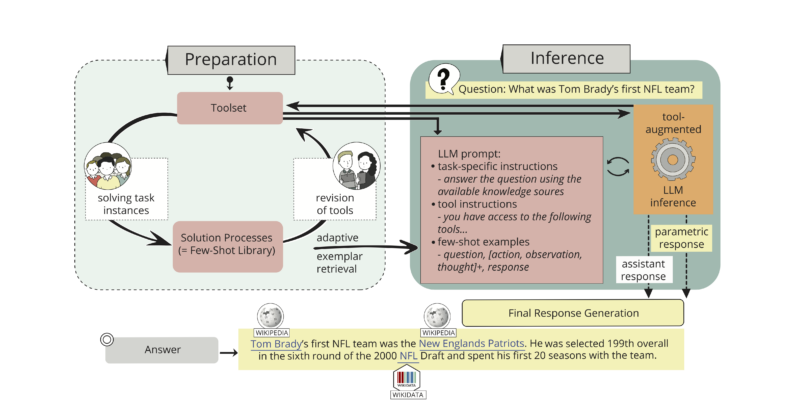
At runtime, the LLM prompt is then enriched with instructions for using tools and an appropriate subset of solution processes. Solution processes describe how those tools can be combined to find an answer to a particular question. In particular, they also contain thoughts in natural language that humans use when using those tools and analysing their output. A main difference to other approaches is that we include complete solution processes in the prompt (rather than only an example of using a specific tool). Another difference is that we use an intelligent selection via a DPP (determinantal point process). This allows us to limit the required prompt space while still obtaining significant accuracy improvements by including only 3 solution processes in the LLM prompt.
As indicated by the above results, this method works well for question answering – in the paper, we break down more specifically why this is the case. An important part is that, unlike other methods for question answering over heterogeneous sources, the approach allows information from structured and unstructured sources to be more freely combined, i.e. there are no “boundaries” between different types of information sources. We not only obtain higher accuracy and preferred responses over the GPT-4 baseline, but the approach also provides relevant sources for the claims that are made. Moreover, we can show which input sources are conflicting or confirming for a statement, which is a good indicator for correctness (e.g. for the 30% of all questions for which we obtain the same claims from parametric knowledge, Wikidata and Wikipedia, the factual error rate is 0% in our evaluation). Of course, the benefits do not come for free: Performing look-ups in information sources and allowing the LLM to reflect on the retrieved contents costs time. We will work on improving efficiency in our next version of the work. So stay tuned. 🙂
Our paper provides many more insights. For example, we show that the (i) same information sources with a standard (not human-like) retrieval process surprisingly actually reduce accuracy and (ii) that most of the improvement is not due to the pre-training cutoff of the underlying LLMs. Since HumanIQ is not task-specific and does not require fine-tuning the LLM, it can be applied to other tasks where LLMs need external tools without much effort.
We will present the work at ACL 2024 in Bangkok in August this year – I am looking forward to meeting some of you there. A big thanks to my co-authors Dhananjay Bhandiwad, Preetam Gattogi and Sahar Vahdati for their incredible work.
Pointers:
- Read the paper at Amazon Science
- Github Human-IQ code repository
- Github HQA code repository



{kind=link}
{kind=link}
{kind=link}